Terra seems to have destroyed my output
I am developing this WDL on Terra for a BioData Catalyst fellow. It works fine when run locally, but when run on Terra the final output is destroyed. Call cacheing disabled, delete intermediates disabled. The workflow reports a success, even giving an address to an output that simply does not exist. I downloaded the relevant portion of the bucket via the command line to check it wasn't just the console's GUI, file's still not there. This is reproducible by running the workflow as I did with these inputs.
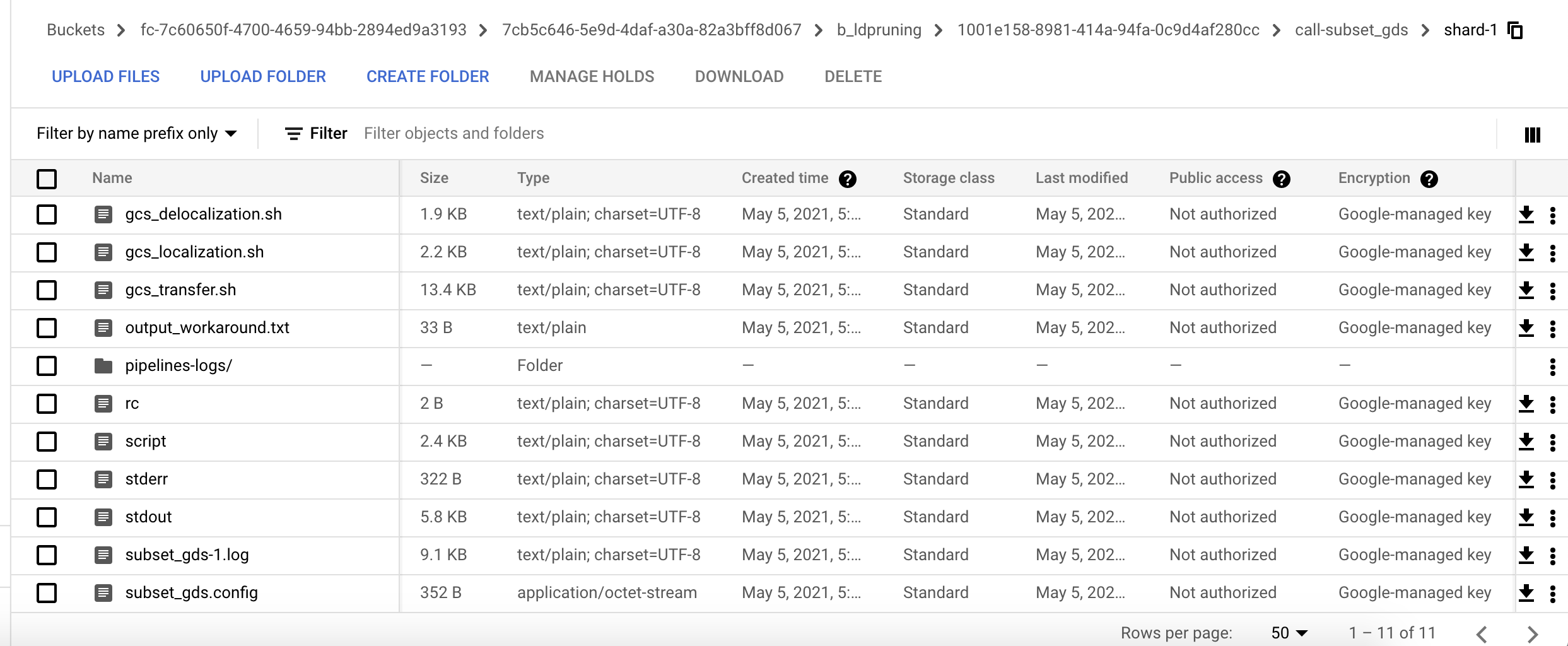
The first task takes in Array[File] of gds and outputs RData representing variants to be pruned. The second task takes in zip(gds, first task's RData) and outputs subsetted gds files. It's that final output that's missing. Oddly, the configuration text file which is also defined as an output for debugging purposes is not deleted, nor is the RData file from the previous step, it's just the subset output.
At first I thought this may be due to how the R script in subset performs cleanup, but this works fine when run on local Cromwell via the Dockstore CLI. (I get that local Cromwell is not as well supported but it is orders of magnitude faster for me to develop locally and just do final tests on Terra.) So that seems to indicate it is a Terra issue, or maybe a GCS issue? That said, this has never happened to me before so I wouldn't be surprised if it turns out to be a quirk of the particular WDL I am writing.
To be clear, I'm not asking for data recovery for my deleted outputs, as each run costs me about eight cents and it's all open data, I just need to figure out how to avoid this issue so I can publish this workflow with confidence.
----
Location of the ghost outputs

Bucket contents
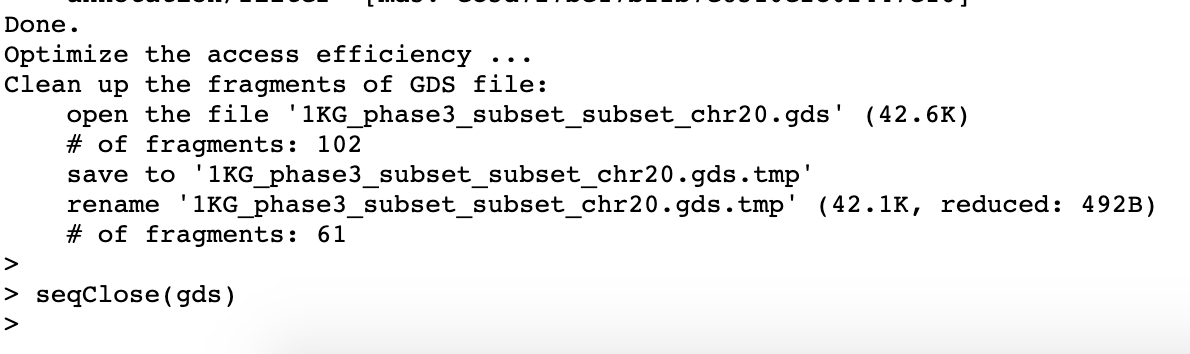
R script cleanup, which might be a red herring, might not?
Comments
12 comments
Hi Aisling,
Thanks for writing in. I'll look over your inquiry and get back to you as soon as I can!
Kind regards,
Jason
Hi Aisling,
I've taken a closer look at your WDL and I noticed you don't have a workflow-level output block: https://github.com/DataBiosphere/analysis_pipeline_WDL/blob/implement-ld-pruning/ld-pruning-wf.wdl#L279-L324
Defining one might make it easy to find the expected final outputs; that said if the workflow outputs are not defined you should see all call outputs as your final outputs.
Do you happen to have a shareable workspace where you've run this code? If so, can you share it with GROUP_FireCloud-Support@firecloud.org, provide a link and a submission ID for where you ran this WDL?
If you don't have a workspace to share, can you provide the workflow ID associated with the run in question?
Kind regards,
Jason
I'll give the workflow level outputs a try.
In the meantime I've added the firecloud support group. It's called "megastep A" and is on the AnVIL Stage Demo billing project. I ran into this bug twice. First run is submission ID 7cb5c646-5e9d-4daf-a30a-82a3bff8d067, second is d8f3bfe9-0cbc-4580-aa4b-8f3d16938bc1 (outputs have a different filename in the second run as I tried to debug the issue but ultimately also went missing).
Hi Aisling,
Thanks for that. My theory is that the output block in the task is not resulting in the expected outcome. I've reached out to one of our engineers for their opinion, and will get back to you once I hear from them. You can hold off on re-writing the workflow if you would like to wait to hear what they say.
I'll also pass the workspace and submission IDs to them.
Kind regards,
Jason
Thanks for letting me know. I'll hold off on the rewrite for now; any insight they provide would be worth its weight in gold if it helps me write better workflows in the future. I am generating the outputs in a bit of an odd way but it works locally; if the method I'm using doesn't work on GCS, I'll be sure to document that for future reference.
It turns out I need to get a working version of this pipeline out sooner than anticipated, so I have to implement a workaround. My colleague Julian came up with one that uses globbing. The workaround still does not use workflow-level outputs, but it is functional on Terra.
I am still interested in learning how the older version of this pipeline failed, as I sometimes guide new users on writing WDLs and want to make sure my own understanding is solid. As far as I aware what I wrote in the old version is in line with the WDL 1.0 spec; if I'm misunderstanding the spec or it does not apply to Terra I'll make note of that. Here is the specific commit that does not include my current workaround if your engineers need a copy of it for reference: https://github.com/DataBiosphere/analysis_pipeline_WDL/tree/6b6b85974b91148693c84e562e88f6d6419b3f18
Hi Aisling,
Thanks for letting us know. The WDL 1.0 spec is definitely the right spec to be working with. I'll give our investigating engineer your latest info for their thoughts. I'm glad to hear Julian was able to find a suitable solution for the time being!
Kind regards,
Jason
Hi Aisling,
One of our engineers was able to identify the reason your original WDL failed to work as expected. Cromwell generally needs to know which files to delocalize before the job starts; the delocalization script is written before any actual work is done. As such, the read_string indirection would not work, as Cromwell would not be able to tell what the file is that needs to be delocalized. The exception to this is glob, which allows for a bit more dynamic delocalization behavior.
I hope this makes sense. If you have any other questions, please let us know!
Kind regards,
Jason
The underlying cause makes sense, but ultimately I'm still confused why Terra reported the workflow a success. Normally, when Cromwell cannot find an output (lets say my output file is merged.gds but I typoed the output section so it expects mergged.gds instead) it will throw an error and the workflow will register as a failure. In this case, it's not doing that, it's blithely treating it as a success and I'm unsure why.
Yeah, it's a great question. Our Batch team sees this as a bug, the fact that Cromwell is not catching this misconfiguration and failing it. They've already written a fix for the bug and it should go out in our next release.
It's currently succeeding because Cromwell is reading this as an optional output. You can see as such in the delocalization script associated with one of the workflows that succeeded (example). It's possible that Cromwell in its current state is misinterpreting the output due to the roundabout way it's defined. The fix that the team developed should make sure this doesn't succeed going forward.
That's interesting. Thanks for the explanation! Does Terra's version of Cromwell match the current release schedule as Cromwell on Github, or is it on its own release schedule?
Cromwell almost always gets put on the Terra release train at the same time it is released to Github. Releases are typically scheduled for Mondays but are delayed on occasion.
Please sign in to leave a comment.