You can import tables of metadata into your workspace by either copying from an existing workspace or importing a TSV file. This article walks through both options.
Option 1: Copy from an existing workspace
Is the source data workspace protected by an Authorization Domain? Make sure the destination workspace has the same Authorization Domain(s) as the workspace where the data are stored. If the destination workspace does not have the same AD, links in the table will not work. This will cause your analysis to fail when Terra cannot localize the data.
1. Go to the data page of the source workspace (that has the data tabley to copy).
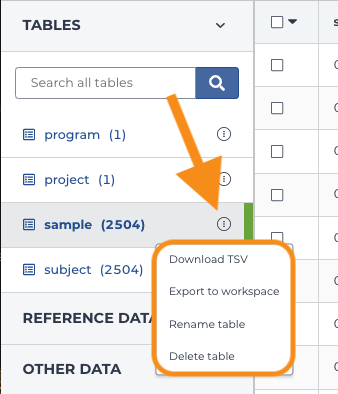
2. Go to the table of metadata to import (i.e. participants, samples, pairs, or sets) and click on the three vertical dots to the right of the table name.
3. Select from the popup menu and follow the prompts.
- To save the entire table to your local machine, use Download TSV.
- To copy the table to another workspace, use Export to workspace.
Importing sets will bring over all the data required for the setAny dependent data will be imported automatically. For example, if you import a sample set, the sample and participant tables and all data linked to the set will also be copied over.
Import conflicts
Note that import conflicts can occur if you already have an entity table in your workspace that matches what you are importing. Terra will notify you that the entity already exists in the workspace.
Copying tables does not copy data files
Copying tables (metadata) from another workspace will not import any linked files into your workspace bucket. File paths (i.e. URLs) in the imported table refer to files in the source workspace storage (i.e. Google bucket). If that workspace storage is deleted, your workspace data model will no longer refer to an existing bucket path.
Option 2: Import a TSV file
You can also import a data table by uploading text files in tab-separated-value (TSV) or tab-delimited (.txt) format. You must use a separate TSV file for each table (i.e. each entity type).
For step-by-step instructions and required file formats, see How to make a data table from scratch or a template.