Learn how to define your schema (data model) and write the JSON for a TDR schema, which specifies your dataset’s tables, their primary keys, and how your tables are related. It's important to do this before creating a TDR dataset.
Note: if you prefer to create your schema without writing any JSON, see Step 2. Build Schema in TDR to learn how to create your dataset and its schema through the TDR web interface.
Step 1. Design your schema
Before writing your schema, you should have an outline of your data model in mind. See Overview: Defining your TDR dataset schema for more guidance on how to develop this outline.
Key elements to think about when designing your schema
- What tables are needed to contain your data, and how are they related?
-
What is the “root entity” table?
The root entity table is the table that includes the primary input data for your dataset. In Terra, this often refers to data that will be used as inputs for a workflow. -
What is each table's primary key?
The primary key is used to uniquely identify each entity in your data (e.g., a subject or sample). Think carefully about this, because you cannot modify the primary keys after creating the dataset. While you can create a dataset without specifying any primary keys, we don’t recommend this because the primary keys are necessary to update your data. -
Make your data findable with a standardized schema.
To make it easier for researchers to find data that are relevant to their work, consider using or adapting a standardized schema, such as the GA4GH Data Use Ontology.
Example: AnVIL core findability schema
An example of a standardized TDR schema designed for greater findability across multiple datasets is the AnVIL core findability schema (see details and a template in GitHub).
Required entities (biosample, donor, and file tables)
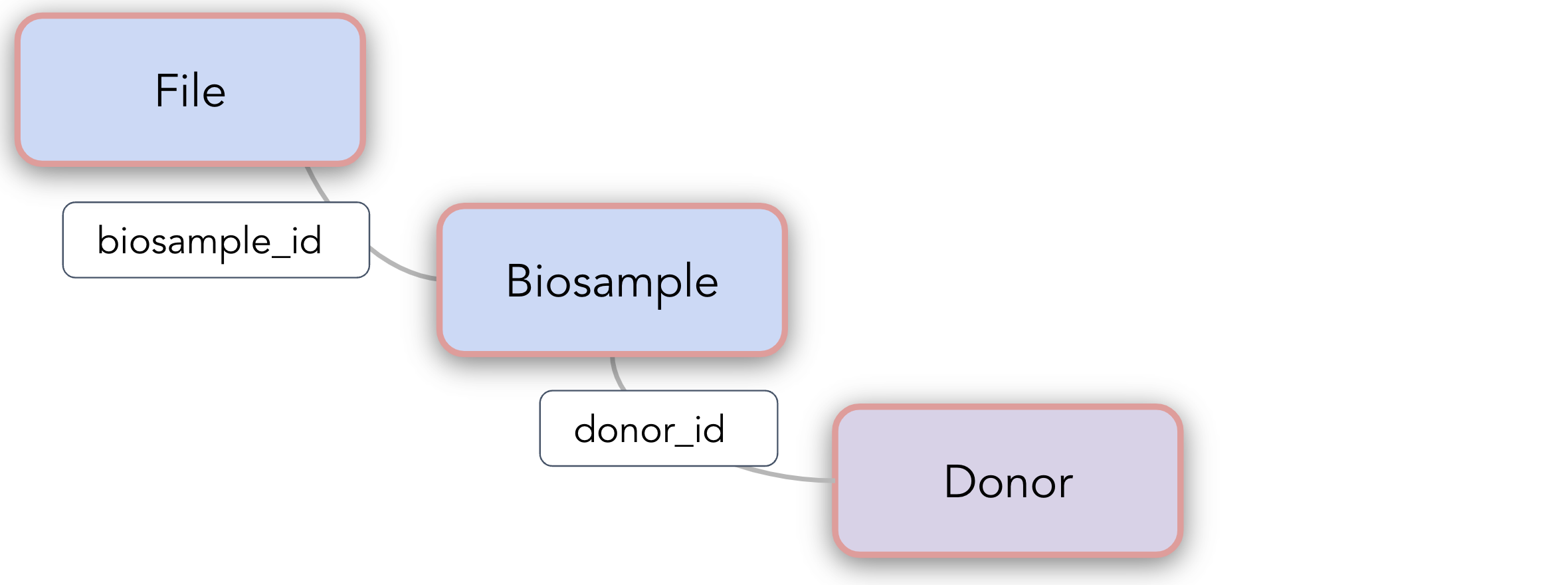
Example TSV: Biosample table
| biosample_id | anatomical site | apriorii_cell_type | apriori_cell_type_code | donor_id |
| bio123890 | blood | abnormal cell | CL:0001061 | do123 |
| bio234789 | blood | normal cell | CL:0001061 | do123 |
Example TSV: Donor table
| donor_id_id | organism_type | phenotypic_sex | reported_ethnicity | genetic_ancestry |
| do123 | homo_sapiens | female | Asian | unknown |
Optional entities/nodes
Step 2. Write the schema JSON
JSON versus in TDR Note that you can also create your schema directly in the TDR website, rather than writing it in JSON. Learn how to do this in Step 2. Build Schema in TDR.
The steps and examples below illustrate how to write your schema in JavaScript Object Notation (JSON) and store it in a .json file.
JSON components
Two major components make up the schema's JSON:
- Tables: Names and types for BigQuery tables and columns
- Relationships: Links between columns
- (optional) Assets: Subsets of your columns, which you may want to share with others
1. Tables
Tables are declared as JSON objects with keys for
- A name with a max length of 63 characters (matching the regex '^[a-zA-Z0-9][_a-zA-Z0-9]*$')
- An optional partitioning “mode” with corresponding settings
- A list of columns
- A list of primary-key column names
- Primary keys are necessary any time you want to update your data. They are technically optional, but highly recommended. You cannot specify your tables' primary keys after creating the dataset.
- If a column’s name is included in the “primaryKeys” list of its parent table, it will be mapped to a BigQuery column with a REQUIRED mode. Otherwise, the column will be mapped to a NULLABLE mode.
- Important note: Setting column names as "primaryKeys" will not work if the column's "array_of" is set to "true", since primary keys can't be arrays.
The specified table name will be the name of the corresponding BigQuery table.
- Tables can be partitioned in BigQuery to reduce query runtime and cost. The top-level “partitionMode” key in each table model specifies one of:
- “none”, to create an unpartitioned table
- “date”, to create a table partitioned by either ingest date or the values in a date column
- “int”, to create a table partitioned by the values in an integer column
BigQuery best practices suggest always partitioning your tables, using the ingest date if there is no other meaningful choice in the table’s columns. These options map directly to corresponding BigQuery partition settings; see the BigQuery docs for more details.
- If the “date” mode is specified, “datePartitionOptions” must also be specified. The options are a JSON object with a single key for “column”. The value of that key must be either “datarepo_ingest_date” (to partition by ingest date), or the name of a column in the table with datatype DATE or TIMESTAMP.
- If the “int” mode is specified, “intPartitionOptions” must also be specified. The options are a JSON object with four keys:
- “column”: The name of an INT64 or INTEGER column in the table
- “min”: The smallest value in the column that should be partitioned
- “max”: The largest value in the column that should be partitioned
- “interval”: The range-size to use when dividing values between “min” and “max” into partitions
Columns
Table columns are also represented as JSON objects, with keys for
- A name, with the same restrictions as table names
- A data-type (e.g., string, number, boolean). Data types are set for each column (i.e., separately for each column block).
-
When creating a dataset in TDR, you will need to supply the data type for each column. Most TDR types “pass-through” to BigQuery types of the same name. A few extra types are supported by the TDR, either as a convenience or to add more semantic information to the table metadata.
Use the table below to help guide your choices. To learn how to format data of each type, see the BigQuery or Synapse documentation.
TDR Datatype
BigQuery Type
Synapse Type
Examples/
WarningsBOOLEAN
BOOLEAN
BIT
TRUE and FALSE
BYTES
BYTES
VARBINARY
Variable length binary data
DATE
DATE
DATE
'YYYY-[M]M-[D]D'
4-digit year, 1 or 2-digit month, and 1- or 2-digit date
DATETIME
DATETIME2
YYYY-[M]M-[D]D[( |T)[H]H:[M]M:[S]S[.F]]
Note: Datetime and Time data types do not care about timezone. BQ stores and returns them in the format provided.
TIME
TIME
[H]H:[M]M:[S]S[.DDDDDD|.F]
Note: TDR currently only accepts timestamps in timezone UTC. BQ stores this value as a long. In the UI, we do the conversion to UTC timestamp. However, the result from the previous data endpoint is a long value. If you are directly using our endpoint, you will have to perform this conversion to have an understandable value.
TIMESTAMP
DATETIME2
Format: YYYY-[M]M-[D]D[( |T)[H]H:[M]M:[S]S[.F]][time zone]
FLOAT
FLOAT
FLOAT
Float and Float64 point to the same underlying data types, so they are equivalent. FLOAT64
FLOAT
FLOAT
INTEGER
INTEGER
INT
INT64
INTEGER
BIGINT
NUMERIC
NUMERIC
REAL
For very large float data or for data where calculations will be performed on the data. STRING
STRING
varchar(8000)
TEXT
STRING
varchar(8000)
FILEREF
STRING
varchar(36)
Stores UUIDs that map to an ingested file. This is translated to DRS URLS on snapshot create. DIRREF
STRING
varchar(36)
Object file (in cloud storage) metadata To render a column's cells as links to cloud file paths when you export the snapshot to the data tab of your Terra workspace, you must set the data type to fileref in the schema.
- An “array_of” boolean
- A "required" boolean option
Any column with a true value for “array_of” will be mapped to a BigQuery column with a REPEATED mode.
Example JSON (define table columns)
"columns": [
{
"name": "sample_id",
"datatype": "string",
"array_of": false
},
{
"name": "BAM_File_Path",
"datatype": "fileref",
"array_of": false
}
]
Troubleshooting JSON formatting Getting all of the brackets just right in a nested .JSON like this can be a little tricky! To avoid messing up the placement of a comma or a bracket, try a free online .JSON validator.
If you're struggling to create a valid JSON, it may help to copy-paste the example code in the Swagger UI request body for that particular API. You can then make changes to the template incrementally while validating each change.
Finally, certain parameters - such as "tables", "relationships", and "assets" - are expected to be lists, so make sure you include square brackets: [ ]
2. Relationships
If there are any connections between columns or tables in your dataset - for example, if the subject_id column in a table storing .bam file references can be used to link samples to demographic data stored in another table - specify them in the relationships field. The relationships object maps one column to another, as in the example below:
"relationships": [
{
"name": "subject",
"from": {
"table": "table1",
"column": "subject_id"
},
"to": {
"table": "table2",
"column": "subject_id"
}
}
]
The best practice is to include relationships that link all of your dataset's tables in the schema, to make it easier to share subsets of the data in snapshots later on. This could mean linking all tables to all other tables, linking each table to just one other table, or something in between, as long as there's a path to get from any one table to any other table.
If necessary, you can use the addRelationships field in the updateSchema API endpoint to add relationships after the dataset has been created.
3. Assets
Optionally, you can also specify your dataset's assets in your schema. Assets allow you to specify specific columns from the dataset that are available to individuals who want to access your dataset. The assets you share might be different for some individuals than others; for example, you might want to share demographic data with some people, but not with others. You must create at least one asset in order to share the data as a Snapshot. See How to create dataset assets in TDR to learn how to specify your assets in your schema.
Example JSON object
The JSON object below generates a dataset with two tables, a "subject" table with two columns, and a "sample" table with three columns. The tables and columns are defined in the “tables” section of the JSON. The relationship between the matching columns is set in the “relationship” section.
Example JSON - Generate two tables connected by matching columns
{
"schema": {
"tables": [{
"name": "sample",
"columns": [{
"name": "sample_id",
"datatype": "string",
"array_of": false
},
{
"name": "BAM_File_path",
"datatype": "fileref",
"array_of": false
}
{
"name": "subject_id",
"datatype": "string",
"array_of": false
}
],
"primaryKey": [],
"partitionMode": "none",
"datePartitionOptions": null,
"intPartitionOptions": null,
"rowCount": null
},
{
"name": "subject",
"columns": [{
"name": "subject_id",
"datatype": "string",
"array_of": false
},
{
"name": "phenotype",
"datatype": "string",
"array_of": false
}
],
"primaryKey": [],
"partitionMode": "none",
"datePartitionOptions": null,
"intPartitionOptions": null,
"rowCount": null
}
],
"relationships": [{
"name": "subject",
"from": {
"table": "subject",
"column": "subject_id"
},
"to": {
"table": "sample",
"column": "subject_id"
}
}],
"assets": [{
"name": "asset1",
"tables": [{
"name": "sample",
"columns": [
"sample_id",
"BAM_File_path"
]
}],
"rootTable": "sample",
"rootColumn": "sample_id"
}]
}
If you’re using the Swagger API endpoints to create or edit your dataset, this .JSON object can be pasted directly into your request body. You can also copy it into a text editor (such as Notepad++, Visual Studio Code, or Atom) and save it as a .JSON file — this is particularly useful if you’re using the TDR UI to create your dataset.
How to retrieve the schema of an existing dataset
It’s often helpful to write a new schema by modifying an existing schema for a dataset with a similar structure. You can view the .JSON for the schema of any dataset to which you have access using the retrieveDataset API endpoint. If you select "SCHEMA" in the include menu, the response body will contain only the schema for the dataset.
Next steps: Create dataset
Once you’ve written your schema in JSON, you can use it to create a new TDR dataset.
If you would rather create your dataset using Swagger APIs, or if your data are stored on Azure, see Create a TDR Dataset with APIs.
And, if you're creating your TDR dataset through the TDR website, see Step 2. Build Schema in TDR to learn how to specify your schema through the TDR website, rather than with a JSON file.